Note: This post is a first attempt to write about topics that are of professional or didactic interest, but which may not be profound enough to merit a separate journal paper or other publication. Some of these topics originated from research-related conversations around campus, and others from internal group seminars in the past few years. I request feedback about length, tone, and format styles.
A. Introduction
There are generally two separate decisions to make in any computational problem. The first is to represent the knowledge about the problem in some useful way. Usually we are required to choose one of several possible representations. The second is to choose a method (or an algorithm) that can operate on the representation to produce the required result. Depending on the representation chosen, there may be several algorithms available to choose from.
From a practical perspective, a good algorithm is often one that is acceptably fast and makes acceptably low demands on system resources (like memory), and the analysis of algorithms is a rich field in its own right with powerful mathematical tools. Choosing the right representation, however, is more often the result of personal or learned experience based on a rare insight than on rigorous analysis. This post shows the importance of knowing what representation to use for what situation.
B. Example
Here’s an example problem (Problem 172 from Project Euler) that shows the importance of the right representation:
How many 18-digit numbers n (without leading zeros) are there such that no digit occurs more than three times in n?
(I recommend that you spend some time analyzing the problem by yourself before reading further).
C. First Representation
Now, what is the first representation that springs to mind? Most of us probably visualized a one-dimensional array, each element representing a digit of the 18-digit number and ranging in value from 0 to 9 (except for the element corresponding to the first digit, which goes from 1 to 9). Let’s call this representation R1.
| Digit |
1017 |
1016 |
1015 |
1014 |
1013 |
1012 |
1011 |
1010 |
109 |
108 |
107 |
106 |
105 |
104 |
103 |
102 |
101 |
100 |
| Values |
1–9 |
0–9 |
0–9 |
0–9 |
0–9 |
0–9 |
0–9 |
0–9 |
0–9 |
0–9 |
0–9 |
0–9 |
0–9 |
0–9 |
0–9 |
0–9 |
0–9 |
0–9 |
Clearly this is a natural first choice for a representation, and a natural choice of accompanying algorithm (algorithm A1) would be a bunch of nested for-loops, one for each digit, with a series of if-else statements buried inside all the loops to check for legality (no digit should occur more than thrice), and a statement to increment a counter for every legal number found. The total time spent inside the loops is then  evaluations, which would take a few hundred thousand years to complete.
evaluations, which would take a few hundred thousand years to complete.
One “refinement” to this brute-force approach would be to use backtracking, which is to bring some of the if-else checks from the deepest for-loop to some of the outer for-loops, so that illegal sub-numbers with just a few digits are trapped and pruned off early instead of letting them grow into full-fledged 18-digit numbers. Let us be extremely generous and say that backtracking would speed up the brute-force algorithm A1 by a million times. The estimated run time is now “only”  loop evaluations, and can be done in a few months.
loop evaluations, and can be done in a few months.
Backtracking has its advantages over brute-force, but thinking up any improvement to the algorithm A1 without changing the underlying representation R1 is essentially an exercise in futility, because at the very least, no algorithm based on A1 can go faster than having to evaluate the number of legal solutions, which could still be intractably large. A better representation is needed.
D. Second Representation
Here are some thoughts:
1. The problem is to find only the number of possible solutions, not to actually list them out. (Knuth[1] calls these two distinct questions “enumeration” and “generation” respectively, which is the terminology I adopt). We need an algorithm that can compute the final number of solutions without having to wade through each individual solution in turn. It’s like the difference between saying “There are  permutations of a deck of cards”, which takes 3 seconds to say out loud (unless you’ve been taking interesting medication), and having to list out all permutations and counting them one by one, which would take
permutations of a deck of cards”, which takes 3 seconds to say out loud (unless you’ve been taking interesting medication), and having to list out all permutations and counting them one by one, which would take  times the age of the universe. We need a representation that will allow such an algorithm to operate.
times the age of the universe. We need a representation that will allow such an algorithm to operate.
2. The number of legal 18-digit numbers (those with at most 3 occurrences of any digit) is less than the number of all 18-digit numbers. We would prefer a representation that allows for only the legal numbers to be represented if possible.
3. If an 18-digit number is legal, then all permutations of its digits are also legal. Additionally, if it is illegal, then all permutations of its digits are also illegal. To restate, what is important for the problem is only the number of instances of each numeral (0–9), and not their position within the 18-digit number itself.
The third point above immediately suggests an alternate representation R2. This representation is a one-dimensional array of length 10, representing the numerals from 0 to 9. The value of each element of the array is the number of occurrences of the corresponding numeral, which we can limit to be in the range [0,3] since we know that no numeral can occur more than 3 times.
| Numeral |
9 |
8 |
7 |
6 |
5 |
4 |
3 |
2 |
1 |
0 |
| Occurrences |
0–3 |
0–3 |
0–3 |
0–3 |
0–3 |
0–3 |
0–3 |
0–3 |
0–3 |
0–3 |
Further, the sum of all the array elements should be exactly equal to the number of digits (18 in this case) of the final number. Even the most basic brute-force algorithm A2 will now have to examine only  = a million cases for validity. It is also easy to speed up algorithm A2 using the equality constraint that the array elements have to add up to 18, by looping through only 9 of the elements and computing the tenth as being 18 minus the sum of the first 9. The number of distinct cases is now only
= a million cases for validity. It is also easy to speed up algorithm A2 using the equality constraint that the array elements have to add up to 18, by looping through only 9 of the elements and computing the tenth as being 18 minus the sum of the first 9. The number of distinct cases is now only  = a quarter million. For each array, the number of distinct permutations of the 18-digit number is given by the multinomial of the array elements:
= a quarter million. For each array, the number of distinct permutations of the 18-digit number is given by the multinomial of the array elements:  . All we need to do is run through the cases, check for validity of the tenth digit, and if so, add the multinomial to the answer. (There’s some minor bookkeeping to keep track of the starting digit not being 0, but it’s easy to figure out). This approach takes about a second to run, depending on what else you have running in the background. As before, it can be sped up by backtracking, using the fact that if a partial sum of the array elements has exceeded 18, then no assignment of values to the remaining elements will reduce it to within 18, and can therefore be pruned off early.
. All we need to do is run through the cases, check for validity of the tenth digit, and if so, add the multinomial to the answer. (There’s some minor bookkeeping to keep track of the starting digit not being 0, but it’s easy to figure out). This approach takes about a second to run, depending on what else you have running in the background. As before, it can be sped up by backtracking, using the fact that if a partial sum of the array elements has exceeded 18, then no assignment of values to the remaining elements will reduce it to within 18, and can therefore be pruned off early.
E. Third Representation
It might look like that is the end of the story, but if we revisit the third point from above, we see that it is only the number of instances of each numeral (0–9) which is required, and not their identities themselves! Representation R1 differentiated between two different numerals and also their position within the 18-digit number. Representation R2 does not bother with the position, but still differentiates between the numerals themselves. Now, we may observe that the number of 18-digit numbers made up of 3 instances each of the numerals {1,2,3,4,5,6} is exactly equal to the number of 18-digit numbers made up of 3 instances each of the numerals {4,5,6,7,8,9}. These were represented two different times in R2, when all we really needed was a way to represent (just once) the fact that 6 numerals were represented 3 times each and the remaining 4 were not represented at all.
Representation R3 implements exactly that, with a one-dimensional array of length 4, representing the number of numerals with 0, 1, 2, and 3 instances each.
| Number of numerals with ___ instances each |
3 |
2 |
1 |
0 |
| Ranges |
0–6 |
0–9 |
0–9 |
0–9 |
Clearly, the sum of the array should always be 10 (being the number of numerals in 0 to 9), and their index-weighted sum  should always be 18 (being the number of digits in the final number). Since each element is required to be a non-negative integer, even a brute force approach A3 has only
should always be 18 (being the number of digits in the final number). Since each element is required to be a non-negative integer, even a brute force approach A3 has only  possibilities for the ith element of the array. The two equality constraints chop off another two degrees of freedom, and even the crudest brute force only lists 7 possibilities for
possibilities for the ith element of the array. The two equality constraints chop off another two degrees of freedom, and even the crudest brute force only lists 7 possibilities for  (from 0 to 6) and 10 possibilities for
(from 0 to 6) and 10 possibilities for  (from 0 to 9), with
(from 0 to 9), with 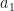 and
and  being computed and checked for legality from and . Out of these 70 possibilities (which can be reduced drastically by adding backtrack to A3), it turns out that there are only 17 legal combinations.
being computed and checked for legality from and . Out of these 70 possibilities (which can be reduced drastically by adding backtrack to A3), it turns out that there are only 17 legal combinations.
| Number of numerals with ___ instances each |
3 |
2 |
1 |
0 |
| a |
0 |
8 |
2 |
0 |
| b |
0 |
9 |
0 |
1 |
| c |
1 |
6 |
3 |
0 |
| d |
1 |
7 |
1 |
1 |
| e |
2 |
4 |
4 |
0 |
| f |
2 |
5 |
2 |
1 |
| g |
2 |
6 |
0 |
2 |
| h |
3 |
2 |
5 |
0 |
| i |
3 |
3 |
3 |
1 |
| j |
3 |
4 |
1 |
2 |
| k |
4 |
0 |
6 |
0 |
| l |
4 |
1 |
4 |
1 |
| m |
4 |
2 |
2 |
2 |
| n |
4 |
3 |
0 |
3 |
| o |
5 |
0 |
3 |
2 |
| p |
5 |
1 |
1 |
3 |
| q |
6 |
0 |
0 |
4 |
(Recall we started with combinations in the first representation). Computing the combinatorics for each of the 17 legal combinations is now a product of two multinomials, one representing the number of ways that ten distinguishable numerals can be partitioned into four sets of sizes through , and the second representing the number of distinct ways that the 18-digit concatenation of those numerals can be permuted. The bookkeeping to prevent the first digit being 0 is a little more involved, and I leave it as an exercise to the reader.
F. Final Thoughts
Here are some final thoughts:
- Representation R1 is unequivocally the wrong representation for this problem. For most problems both R2 and R3 are suitable, but the choice between them depends on the problem instance. For example, if the constraint is to enumerate the number of n-digit numbers no digit of which occurs more than m times, R2 (and A2) will scale polynomially in m with a constant exponent of 10 (the number of numerals), while R3 (and A3) could scale exponentially in m in the worst case. However, it is reasonable to suppose that the average case runtime for R3 and A3 is probably much better than for R2 and A2, as long as the instances are not pathological.
- Algorithm A3 is more complicated than A2, requiring some more bookkeeping. For problems with many edge cases or corner cases, the relative simplicity (and consequently the improved maintainability) of R2 and A2 may be worth the lower execution speed.
- The specific problem chosen in this may be easy, but it captures the issue of choosing good representations for other (more serious) problems. Still, as of date, only 454 people have solved the problem on Project Euler, compared to over 48,000 who have solved the problem of summing all numbers below 1000 that are multiples of 3 or 5, indicating that for every 100 people who know how to use a for-loop correctly, only one knows how to choose a good representation.
- To quote Art Westerberg[2]: “Our ability to enumerate requires we have a way to represent the space of alternatives. Such a representation may be the one real contribution of a Ph.D. thesis — i.e., they are not that easy to discover.”
References:
[1]. Donald E. Knuth, The Art of Computer Programming, Volume 4 Fascicle 0, Introduction to Combinatorial Algorithms and Boolean Functions (2008), ISBN 0-321-53496-4, page 1.
[2]. Arthur W. Westerberg, A retrospective on design and process synthesis. Computers and Chemical Engineering
Volume 28, Issue 4, 15 April 2004, pages 447-458.
Further reading:
1. Edsger Dijkstra’s EWD1250 and EWD1255 are particularly relevant in the context of this post.
2. Donald Knuth’s TAOCP, as always. If you have never read TAOCP before, get thee to a library, go: farewell. Or, if thou wilt needs hyperlinking, hyperlink this. To a library, go, and quickly too. Farewell.
